

BtoBソフトウェア開発は、専用サイトに書いていくことにします。https://microdx.zatturight.com
流行りに触れたら、そこは沼だった
ここ1か月は、今の今まで触れたことが無かったPythonと機械学習(Deep Learning)について、時間の許す限り色々触ってみた結果、今流行っているAIって、実は・・・という感覚に落ち着いたことについて触れます。
当社は今後BtoB市場で戦うべく、新しいプロダクトの開発のため寝る間を惜しんで開発しています。目玉はAI-OCRであり、そこにはAIが欠かせない技術となっています。
当方がプログラマとして社会で働きだしてから25年以上経過していますが、これまで一度もPythonとDeep Learningに触れたことがありませんでした。それは、流行りものは触れたくないという根拠のない気性からでしたが、今回は必要に迫られて初めて経験しました。
Pythonは今一番ホットなプログラミング言語と言っても過言ではないでしょう。インタプリタ言語であり、ライブラリはC言語で書かれているので、一見速そうに感じますが、体感は無茶苦茶遅い。Ubuntu環境で利用するシーンを想定してのことか、Windows環境では顕著に動作速度の遅さを感じます。
なんでこんなに流行っているかといえば、デバッグ実行のし易さとライブラリの豊富さだろう。構文エラーや実行エラーになったときは、必ずコールスタック(実行停止するまでの呼び出された関数が表示される)が表示されてどこで止まったのかがすぐに判るので、直してまた実行という反復がし易い点である。
あとは、C,C++に比べて痒いところに手が届く感じがする。感じがするのはプログラムコードの行数を少なく書けるという意味であり、やっていることはC,C++と何ら変わらない。
Deep Learningのフレームワークはいくつか存在しますが、PyTorchを使って試していました。PyTorchは旧FaceBook社が開発したフレームワークで、ここ4~5年でかなりの利用者数を増やしてきたと思われ、実際ネットで漁っていたサンプルコードは、PyTorchしかありませんでした。
他のフレームワークを試していないので予想でしかありませんが、PyTorchは後発な点と使い易さ・分りやすさが受けているように思います。
機械学習・Deep Learningには、GPUを使うことで高速化できます。NVIDIAのグラフィックボード専用のプログラミング言語であるCudaを使うことで、GPUに搭載されたCuda Coreを並列化処理させることが最大の魅力となっており、一番ホットな開発手法です。Cuda CoreはNVIDIAのグラフィックカードが高価であればあるほど多く搭載されており、多いほどに使用する電力が馬鹿にならないぐらい消費します。
最近そこまで騒がれていないChat-GPTですが、その生みの親であるOpenAIは、Chat-GPI4の学習コストはデータセンター1個分に相当するらしく、既に大規模言語モデルの成長は終わったというようなことを言っていました。機械学習させるコストが膨大過ぎて、これ以上の学習は利益が出せないからといった感じだったと記憶しています。
https://www.gizmodo.jp/2023/04/chatgpt-ai-openai-carbon-emissions-stanford-report.html
で、今回実際にDeep LearningをPCにやらせてみたわけですが、Cuda Core数が多くなければ学習時間はモノによっては1週間あっても足りず、Cure Core数が3倍あるグラフィックカードを使うと1日で終わったので、お金を出せば出すほど優位になります。機械学習自体が予測した通りに動くかはやってみないと分からない点があり、試行回数は重要な要素になります。試行回数を増やすとそれだけ機械学習を回さないといけないので、速く学習できることに越したことはありません。
結局、お金がある企業や研究室が一番優位に立てるモデルになっていると感じました。
機械学習において肝になるのが、データセットです。これはコンピュータにDeep Learningさせるための元となるデータなんですが、これを集める(作る)のが一番大変な作業です。
Deep Learningのアルゴリズムは研究論文が一般公開されており、データセットも公開されているのですが、ことOCRに限っては、英字(アルファベット)しかありません。英字は大文字小文字合わせても50~60通りしかないもので検証されたものしかないため、日本語に対応するためには、新たに機械学習をさせるしかありません。
ここで厄介になるのが、日本語の場合は5万件以上の文字の種類があるのを個人で学習させる煩雑な作業が必要な訳ですが、ここが一番の肝な部分なため、如何に機械学習させていくかが製品品質の向上の鍵となります。
と、ここまで手が掛かるAIなのですが、つい最近までAIの規制についての話題がちらほらありました。
https://nordot.app/1045220482553791140?c=113147194022725109
AIに触れた今、直観人間として思うことは、
「AIが人間を超えることは絶対に無い」
と思いました。
人間が機械を調教しているに過ぎませんから。
未だにOCRで認識率95%以上のアルゴリズムを見たことがありません。英語ならあるかもしれませんが、5万件以上ある日本語の精度を100%にすることは不可能だと思います。
ここまでの実情が分かった1か月でしたが、だからこそ優位に立てるやり方を模索しています。
私がやろうとしていることは、如何に手間を省くかという点です。次回からは、手法そのものはブラックボックスにしますが、精度を向上させた結果について順次記載していきます。
BtoB向けBOTを開発しました。
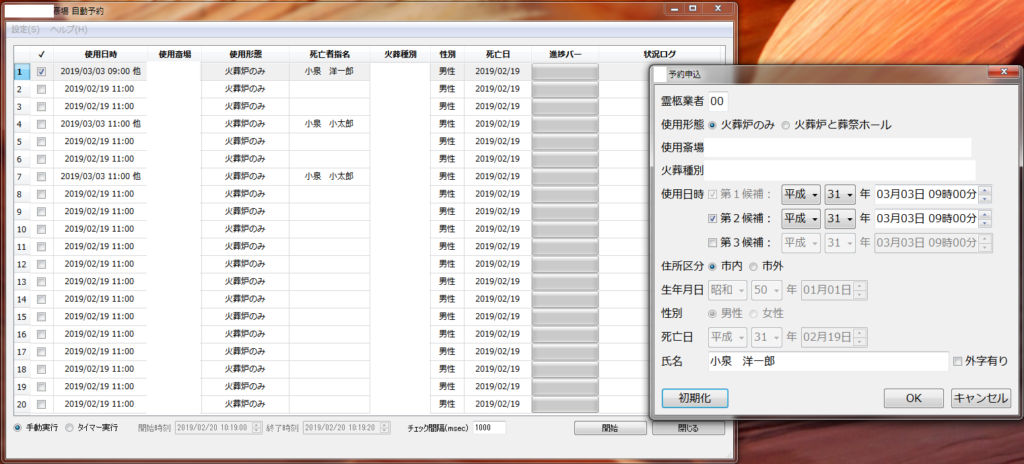
斎場予約を自動化するシステムを開発しました。
本サイトは、1:00~5:00まで閉鎖されており、5:00になると当日から1週間先までの予約が可能になります。朝5時という時間が普通では厳しいにも関わらず、小さなパイを取るための争奪戦が小規模ながらも存在しているということで、自動化の依頼を受けました。
今回は、企業様からのご紹介で実現したものですが、数ある競合の中から当サイトを選んで頂き、誠にありがとうございます!